【画像生成AI】Stable Diffusionの特徴と使い方を、初心者にもわかりやすく解説!

最近流行している、画像生成AI。一度触ってみたいなと思われている方も多いのではないでしょうか。この記事では、代表的な画像生成AIソフトである、Stable Diffusionの概要や基本的な操作法、必要なPCスペックについて、初心者にもわかりやすく解説していきます。画像生成AIに初めて触れる方のための案内として、ぜひご一読ください。
Stable Diffusionの特徴
生成したい画像のイメージをテキスト入力することで、自動で描画してくれる画像生成AI。この記事で紹介するStable Diffusionは、そのなかでも代表的なものです。このソフトは、Web上から利用できるほか、自分のPCにインストールして使うこともできます。ローカル環境で使用する場合、PCには一定のスペックが求められるものの、無料で使用できるので、初めて触れる画像生成AIとして手ごろな存在といえます。
モデルの違いによって、画像の方向性が大きく変化
Stable Diffusionの特徴は、モデルやプロンプトの組み合わせによる無限大の可能性です。モデルとは、画像生成AIが、画像を描くために利用する学習データやアルゴリズムのことで、その種類によって、得意とするジャンルが異なります。たとえば、「Beautiful Realistic Asians v7」というモデルは写真のようにリアルなアジア系の美女の描写を、「Anime Pastel Dream」はパステル系のアニメイラストを得意としています。下に、Beautiful Realistic Asians v7とAnime Pastel Dreamでそれぞれ生成した、サングラスをかけた猫(プロンプト:cat wearing sunglasses)の画像を載せます。

↑Beautiful Realistic Asians v7が描いた、サングラスをかけた猫

↑Anime Pastel Dreamが描いた、サングラスをかけた猫
よく見ると、Beautiful Reailstic Asians v7が描いた猫の目が、人間に似たものになっていることがわかります。これは、同モデルが人間を描くことを得意としているからでしょう。一方のAnime Pastel Dreamでは、サングラスをかけた猫や少女がともに描かれたイラストが生成されました。イラスト調になったのは間違いなくモデルの影響ですが、画像の構図まで、Beautiful Reailstic Asians v7が生成したものとは異なっています。今回は「cat wearing sunglasses」以外の指示は行っていないので、AIが想像力(?)を働かせた結果かもしれません。
モデルを変えることによる影響がいかに大きいか、お分かりいただけたでしょう。モデルは色々なものがインターネット上に公開されており、豊富な選択肢があります。デフォルトで入っているモデルもありますが、能力が高くないので、別のものをインストールするのがおすすめです。
プロンプトを増やして、狙い通りの画像を得る
Stable Diffusionに対する指示を増やせば増やすほど、自分の狙った通りの画像を得やすくなります。たとえば先ほどの「cat wearing sunglasses」に、「summer, sea」を追加してみます。使用するモデルはAnime Pastel Dreamです。

↑プロンプト:cat wearing sunglasses, summer, sea/モデル:Anime Pastel Dream
ネコ耳を付け、サングラスをかけた水着姿の女の子と、猫のイラストが出てきました。Anime Pastel Dreamは、猫だけでなく、人間も一緒に描くのが好きなのかもしれません。
さて、今度は「summer, sea」の代わりに「autumn, forest」と指示しました。すると…

↑プロンプト:cat wearing sunglasses, autumn, forest/モデル:Anime Pastel Dream
紅葉舞い散る森のなかで、人型の猫がサングラスをかけて座っています。今度は人は描かれていません。AIも気まぐれなようです。このように、AIは気分屋なところもありますが、大抵の指示にはちゃんと従ってくれます。プロンプトを増やせば増やすほど、自分の狙いを細かく指示すればするほど、イメージに近い画像が出てくるのです。
モデルとプロンプトの組み合わせ方は、無限大に近いと表現しても過言ではなく、それがStable Diffusionの奥深さを形成しています。また、同じモデルとプロンプトであっても、生成するたびに描かれる画像は変わるので、同じ組み合わせで何度も描画させてみるだけでも面白みがあります。Stable Diffusionの楽しみは、少し触ってみるだけでも体感できるものです。

↑プロンプト:Japanese, maid costume, 25 years old, mini skirt, brown hair, pony tail, red lipstick, closed mouth/モデル:Anime Pastel Dream
ローカル環境で動かすStable Diffusionの操作方法
ここからは、ローカル環境でStable Diffusionを使う場合の操作方法について説明します。以下が、ブラウザ上でのStable Diffusionの操作画面です。本来、Stable DiffusionのUIは英語ですが、拡張機能で日本語化しています。
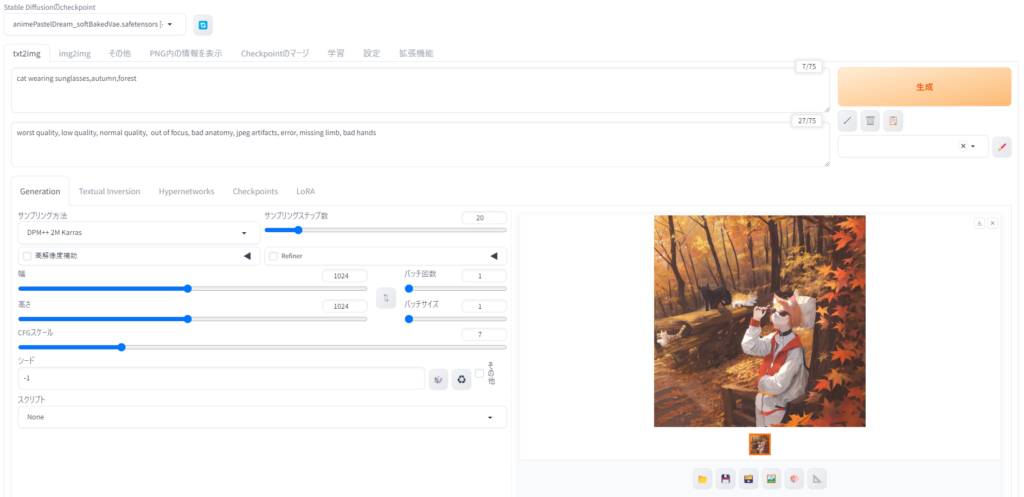
最低限知っておくべき、モデル、プロンプト、ネガティブプロンプト
今回は、初心者が最低限抑えるべき項目について解説していきます。特に重要なのが、モデル、プロンプト、ネガティブプロンプトです。
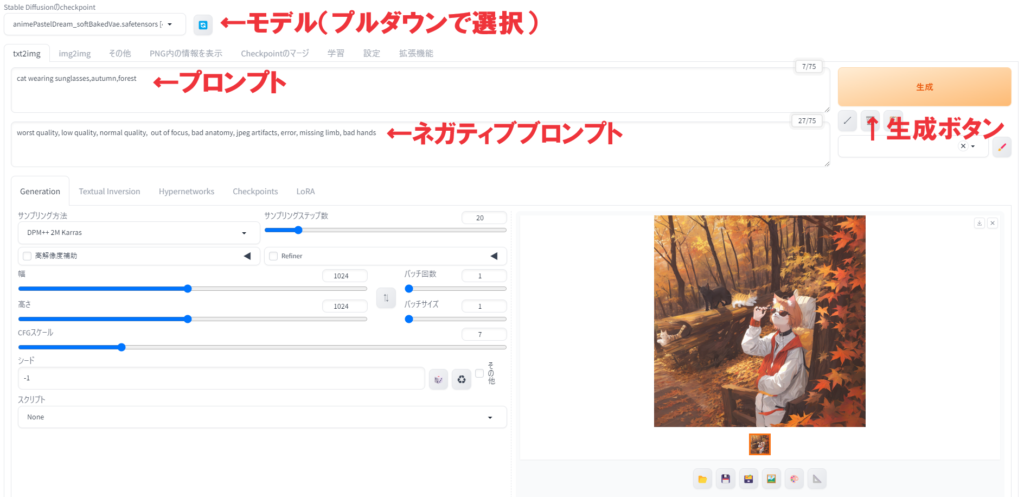
モデルは左上に選択形式で表示されます。ここをクリックすると、インストールしてあるモデルがプルダウンで出てくるので、好みのものを選択します。
AIに対する指示書きであるプロンプトは、自分のイメージを単語で区切り、英語で記入していきます。長い文章にはせず、細かな単語で区切って書くのがコツです。
一方、ここで初めて登場したのがネガティブプロンプト。これは、AIに避けて欲しい表現を指示するものです。今回の例では「worst quality, low quality, normal quality, out of focus, bad anatomy, jpeg artifacts, error, missing limb, bad hands」と記入しています。長ったらしいですが、ざっくり書くと「低クオリティ、ピントがぼけている、手足や指の欠損がある」といった意味の言葉を並べています。
プロンプトをしっかり指示するのは当然として、このネガティブプロンプトも重要です。というのも「低クオリティな画像なんて出てこないだろう」と思ってこれを空欄にすると、変なものがなかなかの確率で出てきます。ネガティブプロンプトに「worst quality」と書くだけでも明らかに効果を実感できるので、書いておくべきです。今回の例で入力したネガティブプロンプトは汎用性のあるものなので、はじめのうちはこれをコピペして貼り付けるだけでもよいでしょう。なお、今回の記事で出しているサンプルには、すべて同様のネガティブプロンプトを打ち込んでいます。
モデル、プロンプト、ネガティブプロンプトを指定してから生成ボタンを押すと、右下に生成した画像が表示されます。最低限、この3つを知っておけば、ある程度の画像生成は可能です。
それ以外の設定は、デフォルトのままでもOK
モデル、プロンプト、ネガティブプロンプト以外の設定は、デフォルトのままでもとりあえずは問題ありません。ただし、左下のGeneratironタブにある幅と高さの項目だけは見ておきましょう。
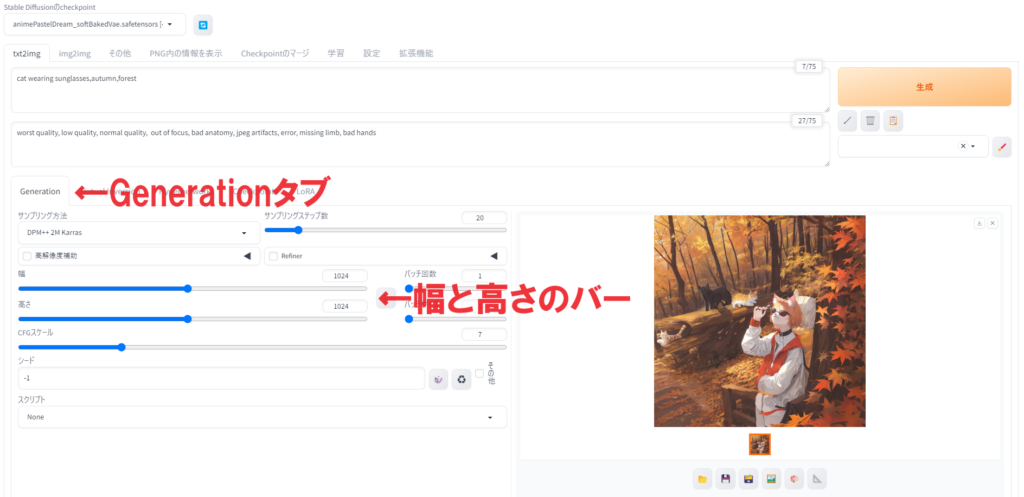
幅と高さは、生成する画像の横縦のピクセル数を表します。デフォルトでは512×512pixとなっていますが、このままだと小さいので、筆者は1024×1024pixにしています。あくまで筆者の体感ですが、長方形より正方形のほうが、いい画像を描いてくれる率が高いような気がします。

↑プロンプト:Japanese, student, teenager, sailor uniform, smile, blush, twintail, library, sitting on a chair/モデル:Beautiful Realistic Asians v7
Stable Diffusionはローカル環境で動かすのがおすすめ
ローカル環境でStable Diffusionを動かすことを想定した話をしてきましたが、Stable DiffusionはWeb上でも使えます。でも、本格的に画像生成AIを試そうと思ったら、ローカル環境のほうがおすすめです。その理由を以下に列挙します。
- お金がかからない
- 生成できる画像の枚数に制限がない
- モデルなどのインストールが容易
- デメリットは、PCのスペックが一定以上必要なことだけ
Stable DiffusionをWeb上で使う場合、いくつかの方法がありますが、そのうち最も主流なのがGoogle Colabを使う方法です。Google Colabとは、ブラウザからPythonを直接記入して実行できるサービス。Stable DiffusionはPythonで動作しているので、これが使えるというわけです。
Google Colabを使うと、画像の生成に必要な処理には外部のGPUが使われるため、自分のPCへの負荷はかかりません。つまり、PCのスペックを気にせずStable Diffusionを始められるというメリットがあります。ですが、Google Colabを使う長所は、これしかないのが事実です。言い換えると、ローカル環境でStable Diffusionを動かすデメリットは、PCのスペックが必要なことだけしかありません。
まず、Google Colabは事実上有料のサービスです。使用するには、1000円強/月のサブスクリプションに加入しなければなりません。また、生成できる画像の枚数にも一定の制限があります。そして、Stable Diffusionに欠かせない、モデルやLoRa(学習モデルのこと)をインストールするのが、ローカル環境に比べて面倒です。ローカル環境の場合、Stable Diffusionがオープンソースなのでお金はかからず、画像枚数の制限もありません。モデルなどのインストールも、ダウンロードしたファイルを指定のフォルダに入れるだけなので容易です。相対的に見て、ローカル環境がおすすめといえます。
ローカル環境でStable Diffusionを動かすのに必要なPCスペック
続いて、ローカル環境でStable Diffusionを動かすために必要な、PCのスペックについてお話します。Stable Diffusionの推奨環境は、以下の通りです。
- OS:Windows(64ビット)
- CPU:特になし
- GPU:VRAM12GB以上
- メモリ:16GB以上
Stable Diffusionを使ううえで、OS、GPU、メモリの3つが重要な要素となります。これらの3要素さえ条件を満たしていれば、Stable Diffusionは(画像生成をさせるだけなら)快適に動作します。CPUにかかる負荷は軽いので、特に高価なものを積む必要はありません。
12GB以上のVRAMを搭載したGPUとしては、GeForce RTX 3060がコスパが高く、おすすめです。なお、3060よりハイエンドなGPU、たとえば3070や3080、あるいは最新世代の4060でも、VRAMは12GB未満なので、単純に高スペックな製品を選んでおけばいいというわけではありません。
ちなみに、推奨スペック以下のPCでは、Stable Diffusionは全く動かないというわけでもなさそうです。筆者がVRAM 8GBのGPUを搭載したPCで検証を行った際、1024pix四方の画像の描画を行うのに2分弱かかって時間的なストレスこそありましたが、エラーは出ませんでした。ただ、GPUは最高80度近辺まで発熱していたので、負荷はかなりかかっていたようです。
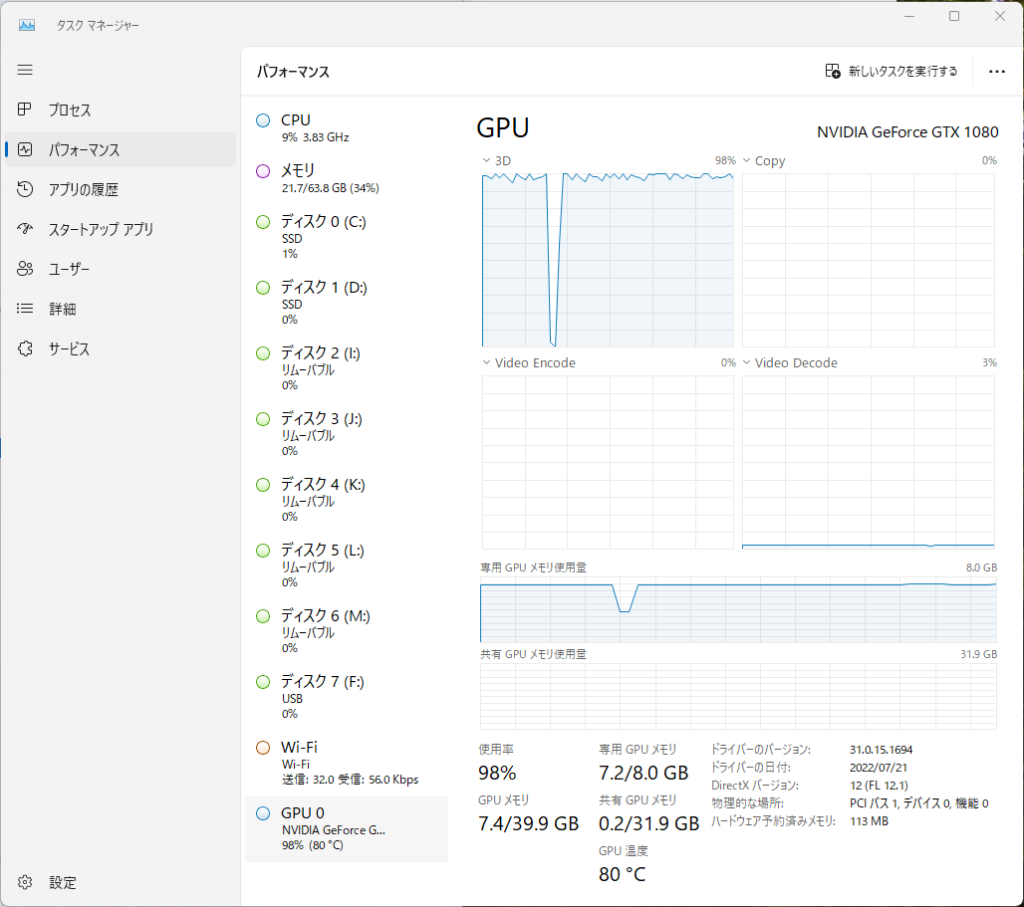
↑筆者のパソコン(GPU:GeForce RTX 1080 VRAM 8GB、メモリ:64GB)の環境で、Stable Diffusionによる画像生成をしているときの負荷状況。GPUにかなりの負荷がかかっています。メモリも21.7GB使用しているので、可能なら32GB以上積んでおいたほうがいいかもしれません。
気になる人は、とりあえずインストールしてみましょう
Stable Diffusionをローカル環境で使うには、PythonやGitのインストールから始めねばならないうえ、ソフト本体のインストールにもかなりの時間を要します。正直、面倒です。とはいえ、主に時間がかかるのはソフト本体のインストールだけなので、夜寝る前にスタートして画面だけ消しておけば、朝起きたころには終わっています。PCを一晩放置するだけと考えれば、負担が軽くも感じられるのではないでしょうか。気になっている方は、とりあえずインストールしてみることをおすすめします。
実際、筆者も初めて触れる画像生成AIとして、Stable Diffusionを使ってみて、楽しみと奥深さを感じました。いまは「これを使いこなすのは並大抵ではないぞ…」という思いが強くなっています。画像を生成して何に使うのか…という目的を置いておいたとしても、最新の技術に触れるという意味で、興味深い経験になることは間違いありません。


